LEFT OUTER JOINで左側にだけ結合条件つけても意味なし
下記のような左テーブルにしか効かない結合条件しても意味無し。
左側は全て出力されるので。
select * from lefttable L left outer join righttable R on L.TENPO = '001' --⇐左テーブルにだけの結合条件
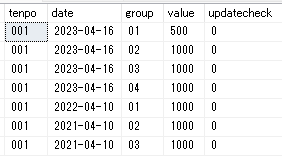
例:テーブル2と3を結合
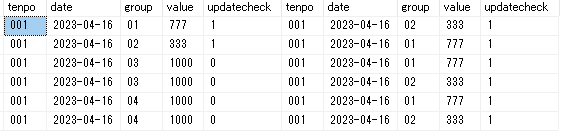
・まずは普通の結合
SELECT * FROM Table3 t3 LEFT OUTER JOIN table2 t2 ON t3.tenpo = t2.tenpo and t3.[group] = t2.[group]

・左側にだけ結合条件つけるSQL
SELECT * FROM Table3 t3 LEFT OUTER JOIN table2 t2 ON t3.tenpo = t2.tenpo and t3.[group] = t2.[group] and t3.tenpo = '002' --⇐左側テーブルにだけ結合条件

左側(テーブル3)は「 t3.tenpo = '002'」以外も全部出力されるので意味なし。
結合条件を複数テーブルにするときは注意
下記はテーブル1・2・3を結合するSQL。1と2は普通に結合。3は1と2両方を結合条件に入れている。
SELECT * FROM Table1 t1 LEFT OUTER JOIN table2 t2 on t1.tenpo = t2.tenpo and t1.[group] = t2.[group] and t1.date = t2.date LEFT OUTER JOIN Table3 t3 on t1.tenpo = t3.tenpo --table1と3 and t1.[group] = t3.[group] --table1と3 and t2.date = t3.date --ここだけtable2と3で結合。テーブル1にはないけどテーブル2にはある日付と結合したいんだよなあという時。
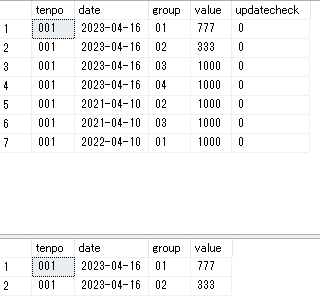
・イメージ
t1.date = t2.date でテーブル1にない日付はテーブル2部分もNULLになっている。
t2.date = t3.date でテーブル1にはないけどテーブル2にはある日付と結合しようとしてもそこはNULL。結合できない。

")