SQL関連で勉強したことのまとめ記事。
長くなってきたのでリンク集として使っていきたい。
SQL実行順序
FROM
JOIN
WHERE
GROUP BY
SUM, MAXなど
HAVING
SELET,DISTINCT
ORDER BY
LIMIT
ちなみにサブクエリは内側から最初に実行される。
小技集
select 1
select 1 from table~という謎のSQLに出会った。
exists文で使われるものらしい。
存在するかどうかだけがわかればよくて、データは要らないよって時に使う。
ただ、select 1 より select * のほうが早いらしい↓
COUNT(*)とCOUNT(1)の処理速度検証結果
もっと言うとexistsよりjoinのほうが早いらしい↓
EXISTSとSQLの高速化について - 猫好きモバイルアプリケーション開発者記録
-- A.name = B.nameである行だけ抽出
select * from Atable AS A
where
exists(
select 1 from Btable AS B
where
A.name = B.name
)
-- -- A.name = B.nameではない行だけ抽出
select * from Atable AS A
where
not exists(
select 1 from Btable AS B
where
A.name = B.name
)
where 1 = 1
where はtrueかfalseかで判定している。
1 = 1なら常にtrue。
使い所はwhere句かand句かの分岐の時。
よく複数単語検索なんかで使う。
検索条件が増える度にAND句で追加したいんだけど、最初はWHERE句じゃないといけないのでめんどくさい。
そこで WHERE句を1=1にして、AND句の追加だけで良いようにする。
select * from where 1= 1 and~ // ここに追加していく
・参考サイト
「WHERE 1=1」は条件付きSQL文が書きやすくなる魔法の言葉 | キノコログ
OFFSET FETCH
MySQLのLMIT OFFSETと同じで取得する行数を指定できる。
OFFSETでスキップする行数を指定。
FETCH NEXT ○ ROWS ONLYで何行取得するかを指定。
select user_id, name from account_table order by user_id OFFSET 10 ROWS FETCH NEXT 5 ROWS ONLY;
11行~15行を取得。
・参考
count(*)over()
window関数。
ページングの時にとても便利!
selectで総レコード数を取得しつつ、1ページ分のselect結果も欲しいときに使える。
secect count(*)over() , account_name from account limit 0 rows fetch 100 rows
・参考記事
テーブルデータ増殖技(Insert Select)

・SQL
id = A を id = B にしてそれ以外の列はそのままで増殖する。
insert into increse select name, 'B' from increse where id = 'A'
イメージとしては下記SQLを実行している感じ。
INSERT INTO table (name, id) VALUES (SELECT文)
insert into increse (name, id) values (select name, 'C' AS 'id' from increse where id = 'B')
GROUP BY句にないカラムも表示させたい
Group By句にないカラムを表示させたい - okinawa
テーブル同士の比較
ファイル取り込み(bulk insert)
テキストやCSVファイルをDBにインポートするときに使う。
SQL Server で BULK INSERT をつかってcsvなどのデータを取込む方法 #SQL - Qiita
テーブルコピー(select * into)
SELECT * INTO コピー先テーブル名 FROM コピー元テーブル名;
基礎知識
GROUP BYってなんなの?
部分集合に切り分ける。
GROUP BYってなんなの? - okinawa
NULLとの四則演算は必ずNULLになる
1 + NULL = NULL
5 * NULL = NULL
集合指向言語と手続き型言語の違い
集合指向言語:まとめて処理
手続き型言語:1件ずつ処理
集合指向言語と手続き型言語の違い - okinawa
HAVING句を理解すると集合志向が理解できるらしい
HAVING句をマスターすると集合志向が理解できるらしい - okinawa
3値論理
普通は TRUE/FALSEの2つ
SQLは TRUE / FALSE / UNKNOWN の3つ
真理値の優先順位は下記↓
- AND:FALSE > UNKNOWN > TRUE
- OR: TRUE > UNKNOWN > FALSE
バッファプールとログバッファ
- バッファプール:ストレージ(HDD)にあるRDBのデータの一部を保持している。
- ログバッファ:更新処理のときに更新情報をログバッファ上にためて、コミット時にまとめて行うための領域。
豆知識
COUNT(*)とCOUNT(列名)の違い
- COUNT(*):NULLも含む全行カウント
- COUNT(列名):NULLではない行数カウント
ちなみにAVG()はNULLの行はカウントしないで計算する。
相関名(AS~)の有効範囲
()内の名前は()の内側のみで使用可能。
外側では使用不可。
これは実行順序の問題。
サブクエリは内側から実行される。
実行された後は実行結果しか残らないので名前はもう残っていない。。。
なんかかっこいい。
ほかにもSELECT句でつけたAS名がWHERE句で使えないのもSELECT句の方が実行順序が後だから。
UNIONの使い所
異なるテーブルをまとめて集計したいとき。
UNIONの使い所 - okinawa
CASE式のELSE句は必ず書くべし!
ELSEは省略するとNULLが入ってしまうので。
SQL CASE式について - okinawa
サブクエリの実行順序と相関サブクエリ
サブクエリは内側から実行される。
SQL サブクエリについてのメモ - okinawa
特性関数とは
ある値が集合に含まれるか調べる関数。
集合に対する条件判定や集計に便利な関数です。
【SQL】特性関数とは - okinawa
SQLチューニング
実行計画の見方。
GUIで見る方法もある↓
実際の実行プランの表示 - SQL Server | Microsoft Learn
チューニングについては過去記事も参照↓
インデックスって何なの?
SQLチューニング方法一覧
統計情報とは
実行計画を練るためのネタ元。
統計情報を更新するだけでパフォーマンス改善する場合もあり。
一時テーブル
大量データを持つテーブルを何回も読み込むとパフォーマンスが悪化する。
そのため一部データを取り出して、一時テーブルを作り、一時テーブルを読み込む。
一時テーブルに主キーを設定してやると尚良し。
テーブル結合関連
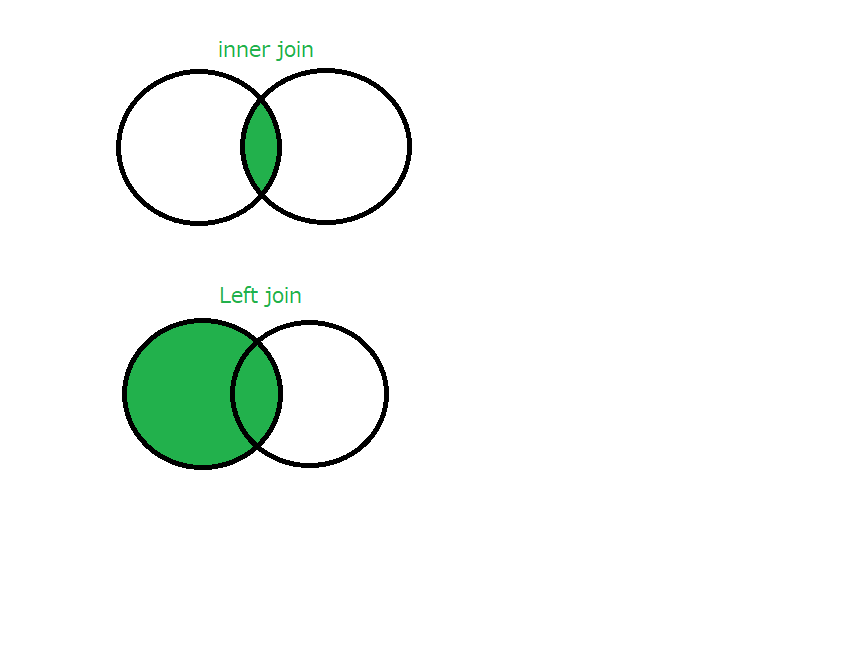
inner join と outer joinの違いはベン図で表すとわかりやすい
・参考記事
SQL Joinサンプル集 Joinで遅いSQLの原因を調べる方法 | ポテパンスタイル
Isn't SQL A left join B, just A? - Stack Overflow
on句が一部合致するとどうなるの?
下記の2テーブルをleft outer joinで実験。


select * from Shohin left outer join Zaiko on Zaiko.name = Shohin.shohin_mei and Zaiko.category = Shohin.shohin_bunrui;
・結果
on句が全部合致した行だけ値が入って結合されている。1行目と3行目。
on句が一部合致した行は全部nullで結合されている。4行目。
すべて合致した行のみ結合され、それ以外はNULLで出力されるということ。

on句をwhere句っぽく使うときの注意点
・torihikijiyuテーブル

・haishi_kouzaテーブル

・SQL文(right outer join)
select * from haishi_kouza right outer join torihikijiyu as tor on tor.torihikijiyumei = '契約' --where句っぽいところ

上記のように取引事由が「契約」以外の行も出力されてしまう。
right joinの場合は右側のテーブルは結合条件に合致しなくても全て出力される。
そのためtorihikijiyuテーブルの行はすべて出力。
この場合は、leftかinner joinにすれば取引事由が「契約」の行のみ出力される。
あれ?どゆこと?
where句と同じことになると思ってたけどそうじゃないようで。
どうやらouter側のテーブルは全部返ってくる。
でも inner joinの時はwhere句みたいな動きをしている。(SQL1) ま、where句みたいに使いたいならwhere句を使いましょう。
→where句よりjoin句で絞り込んだほうが処理が早いらしい。
・SQL文1(left join)
select * from haishi_kouza left join torihikijiyu as tor on tor.torihikijiyumei = '契約'

結果は廃止口座テーブルの全ての行に取引事由テーブルの「契約」の行だけが結合される。
ここのまとめ
結合の向きに注意する。
・tableA left join tableB
tableB.columnB = '契約' にすると「契約」の行のみ結合して出力。
・tableA right join tableB
tableB.columnB = '契約' にすると「契約」以外の行も全て出力されてしまう。
テーブル結合ってなんなの?(重要)
無条件テーブル結合をやってみたらわかりやすかった。
・torihikijiyuテーブル
・haishi_kouzaテーブル
・SQL(無条件結合)
select * from haishi_kouza inner join torihikijiyu as tor on 1 = 1
・結果

テーブル結合ってのは
列は、tableA + tableB
行は、tableA × tableB
になるんだなあ。
外部結合ミスの見つけ方
外部結合が上手くいってなくて不要な行が出力されたり、nulで出力されて困った時に。
- nullではないはずのカラムがnullだったら外部結合ミスを怪しもう。ON句の結合ができない行はnullを含んで出力される。
- 妙なところにMAXやMINが使われていたら外部結合ミスを取り繕っている可能性あり
テーブル結合で行を増殖させないポイント
ON句の条件を
- 1対1で結合
- 1対多で結合
【SQL】テーブル結合で行を増殖させないポイント - okinawa
集合演算をテーブル結合でやってみる
テーブル結合ハマったこと
論理と集合
分配法則
掛け算と同じ。
A & (B or C) == (A & B) or (A & C)
A or (B & C) == (A or B) & (A or C)
ドモルガンの法則
!(A & B) == !A or !B
!(A or B) == !A & !B
対偶とごっちゃになるので注意。
SQLを読むときのポイント
- 最初にSELECT行を見て何を取得するか把握する
- 最初のFrom句のテーブルがメインテーブル
- group byやsumなどの集約関数を見ると何を集計したいのかわかる
- ネストの深いところから見ていくと割とわかりやすい
SQLテストサイト
ブラウザでSQLを実行できる便利サイト↓
sqlfiddle.com