和集合:UNION / UNION ALL
差集合:EXCEPT
積集合:INTERSECT
関係除算:なし
和集合:UNION / UNION ALL
UNIONは重複削除。
UNION ALLは重複も含む。こっちのが処理速度速い。
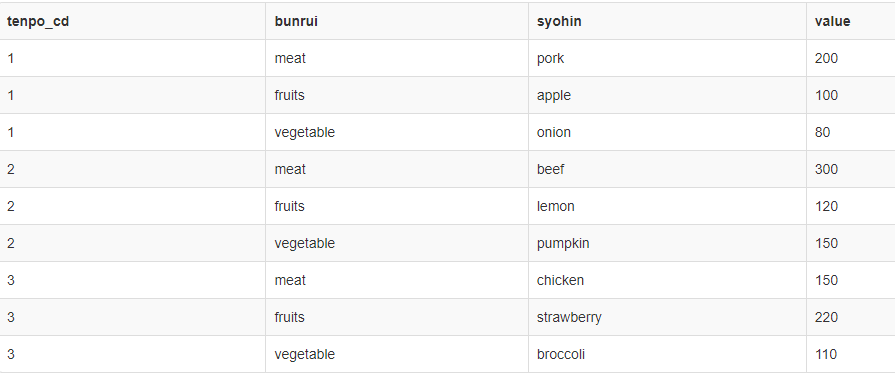
↑元テーブル(classaとclassb)
テーブル結合ではFULL OUTER JOIN。
select * from classa a
full outerjoin classb b
on a.name = b.name
select name from classa
unionselect name from classb
UNIONは縦に結合。
FULL OUTER JOINは横に結合。
差集合:EXCEPT
引き算。classA - classB
select a.name from classa a
leftouterjoin classb b
on a.name = b.name
where
b.name ISNULL--ここがポイントselect name from classa
except
select name from classb
実行結果
積集合:INTERSECT
select a.name from classa a
innerjoin classb b
on a.name = b.name
select name from classa
intersectselect name from classb
SELECT * FROM classc c1
wherenotexists(
select name from classb
except
select name from classc c2
where
c1.team = c2.team
)
andnotexists(
select name from classc c3
where
c1.team = c3.team
except
select name from classb
)
# 「B - C = 0」 & 「C - B = 0」 なら余りなしの厳密な除算になる
実行結果
HAVING句を使った1対1対応を利用する
select c.team from classc c
leftouterjoin classb b #leftouterjoinon c.name = b.name
groupby c.team
havingcount(b.name) = (selectcount(name) from classb) #結合後のb.nameの数と結合前のb.nameの数の比較
andcount(c.name) = (selectcount(name) from classb) #結合後のc.nameの数と結合前のb.nameの数の比較